PYDB-Q&A
Q&A
例会分享复盘
Li
可拓展方面
你的是csv,那其他数据库存储是啥结构呢
讲述其他数据库在底层存储用的什么(相比于csv)

关于分享的目标
一开始没有说明白你的目标

文件系统只是数据的存储工具,而数据库系统则是数据的管理大师。
比如。原来的时候这个做这个数据操作,输入输出是什么样子?有了数据库以后输入输出又是什么样子?
打算在这结合航空订票例子阐述
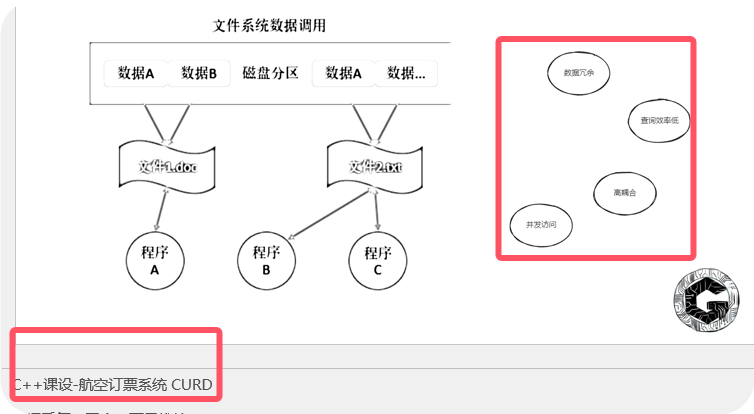
关于存储模块和前端的交互
存储模块其实应该就干存储的事情,和前端的交互应该拆出来
- 其实我这就是返回一个print()消息,直接打印到控制台。我这里简化了
关于SQL编译器规定后端可以接收的格式
翻译解析查询就很笼统
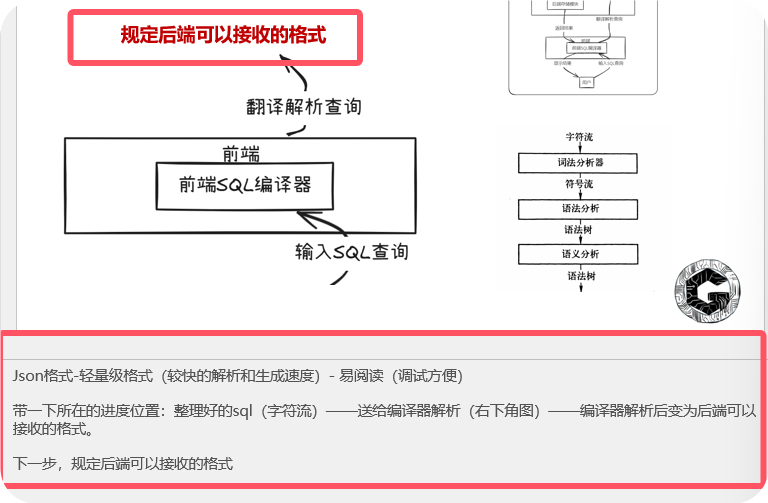
- 加入解释:这个逻辑就很像是咱们常说的机器人,我让他去拿水,然后他把我的语言转化成拿水这个动作,调用它的一些关节模块
关于属性的支持情况
在存储那边关于属性还未做太多的拓展
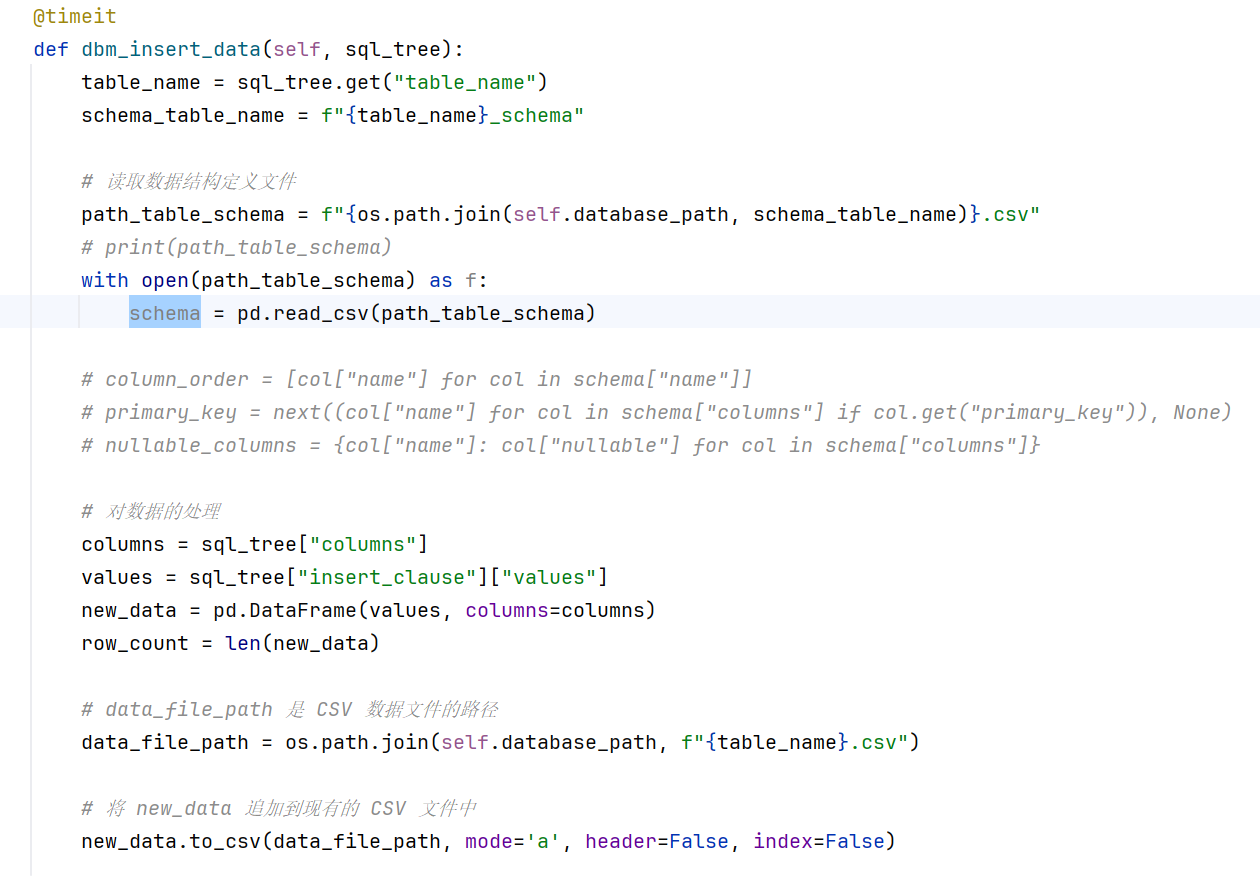
其实有个很暴力的做法,就是拿到schema这里里面的属性,比如not null非空,对tree里的值遍历核验,是否符合要求。
- 其他的属性也是一样,加一层中间层进行合演插入的值和属性是否符合,这个就是语义分析
这个框架打好了,后期拓展挺容易的,就是如果想要优化还得再思考思考
关于性能测试
- mock数据
- 我是写了mock文件,当时其实mock到了1000万行插入的sql。测试没成功就是因为我的db插入太久了hhh
- 还有1000万sql插入mysql还得对mysql做另外的配置,比如最长连接时间,插入文件的最大大小。
- test
- py直接写test文件,用py去连接mysql测试时间,把结果写入txt文件
- 测试pydb也是一样
- 测试的时候发现时间还有有上下浮动的,不管是mysql还是pydb。mysql会更稳定一些。所以多次测量取平均值就很重要。
- mock数据
更进一步建议
其他

Qian
讲完例会反思写下如下问题的答案。
什么是SQL(结构化语言)?
- 讲例会时候从SQL作为第四代编程语言介绍,结合一二三代语言进行阐述,说明SQL语言在历史所处的地位。
- 但发现不够,大一同学来的比较多,SQL这部分确实得需要多介绍些。
- 讲例会时候从SQL作为第四代编程语言介绍,结合一二三代语言进行阐述,说明SQL语言在历史所处的地位。
为什么要用SQL编译器(词法分析、语法分析)?
- 总体来说,用了SQL编译器可以更好的模块分层。对于后端模块就不需要考虑关于空白符,注释等等方便的逻辑处理儿子SQL编译器模块就处理了,这样分离设计有利于简化其中的一项任务。
- 为什么要把SQL编译器分为词法分析和语法分析
- 词法分析
- 如果是硬匹配,可拓展能力不强,对于更复杂,换了形式的SQL语句,匹配规则就会失效。所以需要SQL编译器语法分析,进行更灵活的翻译处理。
- 语法分析
- 在词法分析后,语法分析就可以不用关注于语法规则。
- 总体来说,可以简化每个部分的设计,提高编译器的效率(每个部分要优化的化也更简单)。
- 词法分析
为什么要用 LR(1) 文法?
sly库使用了 LALR(1) 文法。
为什么sly库选择 LALR(1) 呢?
做完例会后反思一下
- LR(1) 文法的优势
- 自底向上分析
- 递推规约方法
- 向前看字符为1,可以解决大部分规约问题
- LALR(1) 在LR(1) 的基础上,简化了构建项目集,对内存要求更小了,更快了。
- LR(1) 文法的优势
mysql是一个非常好的数据库了(至少经过了大量工程检验了),为什么您自己做的数据库在实验数据上比他的好?
另外,我作为技术人员,有一个质疑点
我的猜想(质疑点)有这些:
- 实验环境是否一致
- 选取(插入)的数据是否有普适性
- Mysql是不是为了普适性,放弃了部分性能?
对于我实验做的不严谨的地方
- 计算mysql时间效率时候,把mysql事务时间算上了,这或许就是MySQL在插入数据量为10时候比pydb慢的原因。
- 反思下次实验环境相统一,这样实验才是有意义的。
Tie
例会中,帖老也提到这个问题
除了上面提到的点,还有一个点是mysql的时间是直接根据mysql控制台给出来的,但问题是mysql内部也分层。那mysql计算的是哪几层的内容呢?

Sun
time装饰器计算时间不准确

- 疑问:
- 用装饰器计算时间和直接恰头尾计算时间有误差,还比较大?不知道什么原因
- 我猜测是装饰器包裹的匿名函数只算一层时间?匿名函数如果有嵌套不会被计算在内?
- 感觉还是有点说不通
- 用装饰器计算时间和直接恰头尾计算时间有误差,还比较大?不知道什么原因
- 疑问:
关于
gpu的dbmsgpu做接入层filer,并行,支持给固态硬盘数据直接读取,可用cupy库
模块缺失
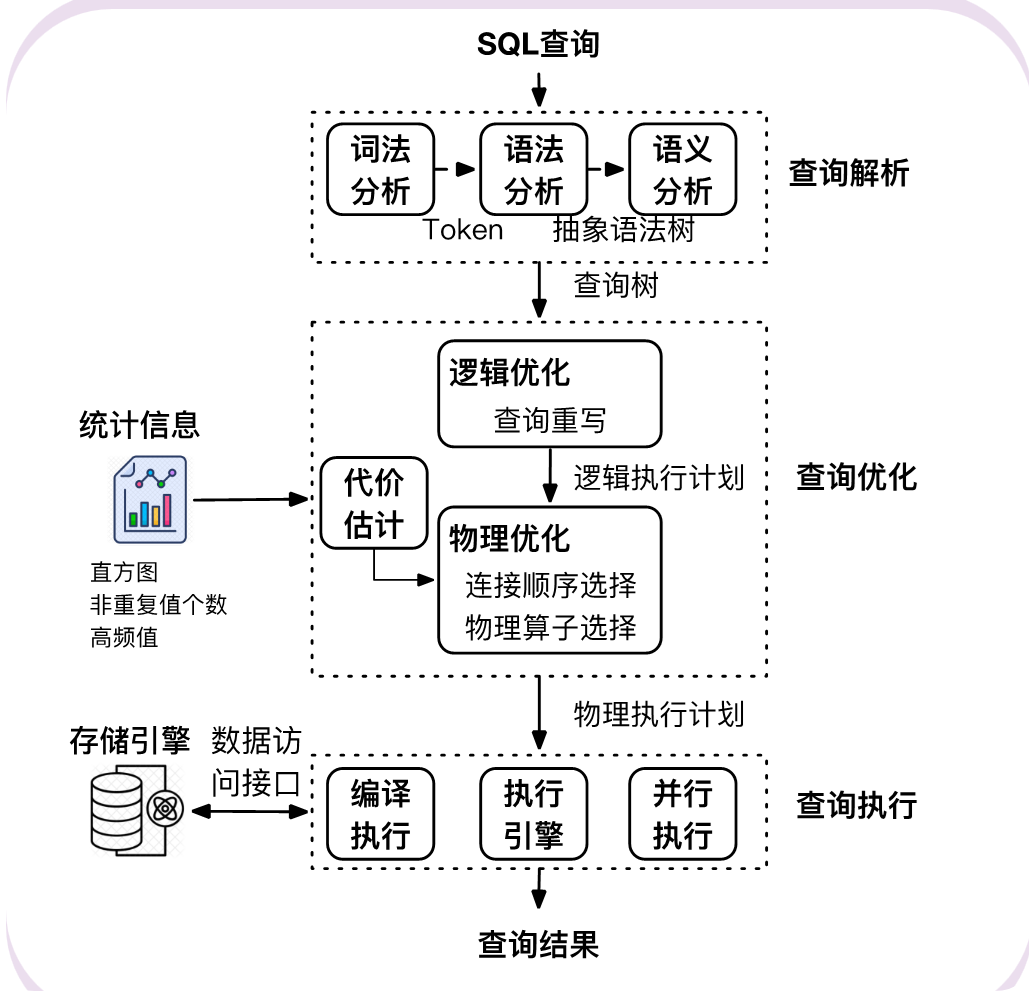
review
AI与DB结合综述
AI4DB
- 先综述再分述???
- 综述用思维导图表示出传统做法与ai结合的做法
- 分述再详细解释
- 强化学习?深度强化学习?
- 先综述再分述???
DB4AI
- 数据库启动AI模型
- 为什么要用python驱动
- LLM?—— 用其他语言会不会更快?
review
传统调优
- DBA 根据经验等方式写在conf 文件中
如何讲综述
- 分享配图
- 要了解技术细节!不明白的内容不要往ppt上放
- ppt中的细节要阐述,让观众听懂
- 分享配图
为什么要了解顺序选择
全排列 —— 贪心算法
- 目的减少连接
- 层次凝聚的思维 —— 从局部到全局逐层构建解决方案
- 目的减少连接
蒙特卡洛树的搜索
蒙特卡洛树搜索是一种通过随机采样模拟的方式来探索决策树的搜索算法
- 并非蛮力法把所有情况都遍历过去,而是发掘探索,边统计
- 次数够多,就可以尽可能接近最优解
成本估计
- 基数估计(查询结果的行数)
列间关联 表间关联
- 贝叶斯统计
- 类的条件估计假设
- 列和列之间是独立的(P(AB) = P(A)*P(B))
- 类的条件估计假设
- 因果图
- 概率图
- 如何获得
- 学习生成
- 需求分析获得
- 函数依赖集
- 反应列和列之间的关联
- 如何获得
- 概率图
- 贝叶斯统计
ai加速数据结构 :thinking:
- 用神经网络替代Btree索引
systemML
执行器
- numpy写
- cupy写
- 存储
- csv —— 加上 buffer
- 添加页面置换界面
- 每次从buffer找,再到磁盘中找
- 选择合适的置换页面