PYDB 手搓部分DB
任务(简易PYDB)
- 能够生成语法树
- 四条语句支持(select 支持嵌套)
词法分析
解析树 是描述文法推导的完整树结构,包含所有的中间步骤;而 语法树 是更简化的表示,突出表达式的语法结构
解析树(Parse Tree)
- 定义:解析树是根据语法规则生成的树结构,反映了输入符号如何根据文法产生的整个过程。
- 结构:每个节点代表一个文法符号(终结符或非终结符),叶子节点是终结符,内部节点是非终结符。
- 细节:包含了文法中所有的产生式和所有的细节,反映了所有的推导步骤。
- 示例:对于表达式
(a + b) * c,解析树将展示如何通过产生式逐步构建这个表达式,包括所有的操作和运算顺序。
语法树(Syntax Tree)
1. 运算符(Operators)
运算符是执行操作的符号,表明如何操作关系或条件。
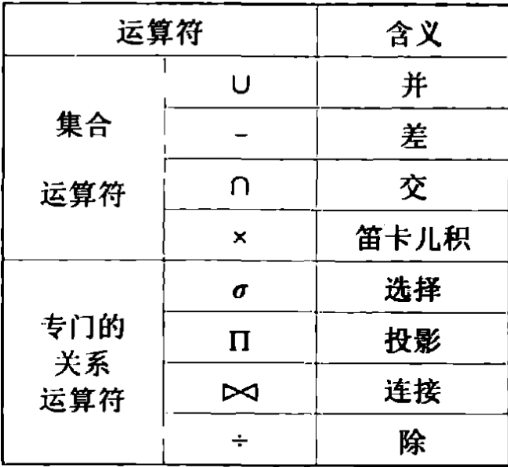
- 选择运算符:
σ(选择特定条件的元组) - 投影运算符:
π(提取特定的属性) - 连接运算符:
⋈(合并关系表) - 集合运算符:
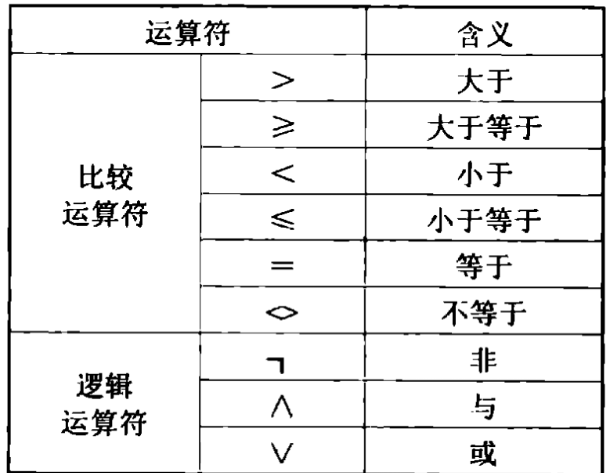
∪,∩,−,x(集合操作,如并集、交集、差集, 笛卡尔积) - 比较运算符:
>,<,=,>=,<=,<>(用于条件表达式中的比较)
2. 标识符(Identifiers)
标识符通常用于表示表、列或属性的名称,具体指代数据库中的对象。
- 表名:
Employee,Department - 属性名:
age,name,department_id
3. 分隔符(Separators)
分隔符用于结构化表达式和分隔不同的部分。
逗号
,用于分隔投影中的多个属性。
- 例:
π name, age (Employee)
- 例:
圆括号
()- 用于分隔不同的关系运算或指定操作对象。
- 例:
σ age > 30 (Employee)
4. 常量(Constants)
常量是用于条件表达式中的具体值,通常不变。
- 例子:
30,'HR',在条件表达式或谓词中用于和属性做比较。
5. 右递归与左递归
右递归(Right Recursion):
右递归是指文法产生式中,非终结符在产生式的右边,且可能递归调用自身。例如:
A → αA | β这种结构会导致深度递归,可能在某些解析器中造成栈溢出。
左递归(Left Recursion):
左递归是指文法产生式中,非终结符在产生式的左边,且可能递归调用自身。例如:
A → Aα | β左递归在 LALR(1) 和 LL(1) 解析器中是不可接受的,因为它会导致无限循环。通常需要将左递归转化为右递归。
sql文法规则
- 使用尖括号
<>包围的部分表示非终结符。 - 终结符用单引号括起来表示终结符
::=:表示”定义为”的意思,
create

优化前
<statements> ::= <create_database> | <create_table> <create_database> ::= 'CREATE' 'DATABASE' 'IDENTIFIER' <create_table> ::= 'CREATE' 'TABLE' 'IDENTIFIER' '(' <create_columns> ')' <create_columns> ::= <create_column> ',' <create_columns> | <create_column> <create_column> ::= 'IDENTIFIER' <data_type> <constraints> <data_type> ::= 'INT' | 'VARCHAR' '(' NUMBER ')' | 'DECIMAL' '(' NUMBER ',' NUMBER ')' <constraints> ::= <constraint> <constraints> | <constraint> <constraint> ::= 'PRIMARY KEY' | 'NOT NULL'优化后
<columns> ::= <column> <column_list> <column_list> ::= ',' <column> <column_list> | ',' <column> | '[]' <column> ::= 'IDENTIFIER' <data_type> <constraints> <columns> ::= <column> ',' <columns> | <column> <column> ::= 'IDENTIFIER' <data_type> <constraints>
自底向上分析顺序执行图
| 已匹配 | 栈 | 输入 | 操作 |
|---|---|---|---|
| $ | CREATE DATABASE test_db$ | 初始状态 | |
CREATE | $CREATE | DATABASE test_db$ | 移入 CREATE |
CREATE DATABASE | $CREATE DATABASE | test_db$ | 移入 DATABASE |
CREATE DATABASE test_db | $CREATE DATABASE test_db | $ | 移入 test_db |
CREATE DATABASE IDENTIFIER | $CREATE DATABASE IDENTIFIER | $ | 规约 IDENTIFIER → test_db |
CREATE DATABASE IDENTIFIER | $Statement | $ | 规约 Statement → CREATE DATABASE IDENTIFIER |
show
<statements> ::= <show_database>
<show_database> ::= 'SHOW' 'DATABASES'use
<statements> ::= <use_database>
<use_database> ::= 'USE' 'IDENTIFIER'insert


# 多行插入:
INSERT INTO students (name, age, major) VALUES
('Bob', 22, 'Mathematics'),
('Charlie', 19, 'Physics');
# 从另一个表插入:
INSERT INTO graduated_students (name, age, major)
SELECT name, age, major FROM students WHERE graduated = true;<statements> ::= <insert_data>
<insert_data> ::= 'INSERT' 'INTO' 'IDENTIFIER' '(' <data_columns> ')' <insert_clause>
<data_columns> 见select
<insert_clause> ::= 'VALUES' <values_clause>
| 'SELECT' <select_data>
<values_clause> ::= '(' <datas> ')'
| '(' <datas> ')', <values_clause>
<datas> ::= <datas> ',' <data>
| <data>
<data> 见selectselect
# 选择所有列:
SELECT * FROM students;
# 简单选择:
SELECT name, age FROM students;
# 带条件的选择:
SELECT name, age
FROM students
WHERE graduated = true
AND age > 20
AND name = 'Ella'
AND NOT age = 25;
# 使用排序:
SELECT name, age FROM students ORDER BY age DESC;
# 连接多个表:
SELECT s.name, c.course_name
FROM students s
JOIN courses c ON s.course_id = c.id;
# 子查询:
SELECT name, age FROM students
WHERE major IN (SELECT major FROM majors WHERE department = 'Science');<statements> ::= <select_data>
<select_data> ::= <select_all>
| <simple_select>
| <conditional_select>
| <ordered_select>
| <join_select>
| <subquery_select>
<select_all> ::= 'SELECT' '*' <from_clause>
<simple_select> ::= 'SELECT' <data_columns> <from_clause>
<conditional_select> ::= 'SELECT' <data_columns> <from_clause> <where_clause>
<ordered_select> ::= 'SELECT' <data_columns> <from_clause> <order_by_clause>
<join_select> ::= 'SELECT' <data_columns> <from_clause_with_alias> <join_clause>
<subquery_select> ::= 'SELECT' <data_columns> <from_clause> <where_in_clause>
<from_clause_with_alias> ::= 'FROM' <data> <data>
<from_clause> ::= 'FROM' <data>
<where_in_clause> ::= 'WHERE' <data> '.' <data> 'IN' '(' <select_data> ')'
<where_clause> ::= 'WHERE' <conditions>
<order_by_clause> ::= 'ORDER BY' <order_clause>
<data_columns> ::= <data> ',' <data_columns>
| <data>
<data> ::= 'IDENTIFIER'
| "'" 'IDENTIFIER' 'IDENTIFIER' "'"
| "'" 'IDENTIFIER' "'"
| 'NUMBER'
<conditions> ::= <condition>
| <condition> 'AND' <conditions>
| <condition> 'OR' <conditions>
| []
<condition> ::= <data> '.' <data> 'OPERATOR' <data> '.' <data>
| <data> '.' <data> 'OPERATOR' <data>
| <data> 'OPERATOR' <data>
<order_clause> ::= <data> ASC
| <data> DESC
<join_clause> ::= 'JOIN' <data> '.' <data> 'ON' <condition> //只处理带别名的情况# 11.6日修改
<statements> ::= <select_data>
<select_data> ::= <select_all>
| <simple_select>
| <conditional_select>
| <ordered_select>
| <join_select>
| <subquery_select>
<select_all> ::= 'SELECT' '*' <from_clause>
<simple_select> ::= 'SELECT' <data_columns> <from_clause>
<conditional_select> ::= 'SELECT' <data_columns> <from_clause> <where_clause>
<ordered_select> ::= 'SELECT' <data_columns> <from_clause> <order_by_clause>
<from_clause> ::= 'FROM' <data>
<where_clause> ::= 'WHERE' <conditions>
<order_by_clause> ::= 'ORDER BY' <order_clause>
<data_columns> ::= <data> ',' <data_columns>
| <data>
<condition> ::= <data> 'OPERATOR' <data>
<data> ::= 'IDENTIFIER'
| "'" 'IDENTIFIER' 'IDENTIFIER' "'"
| "'" 'IDENTIFIER' "'"
| 'NUMBER'
<conditions> ::= <condition>
| <condition> 'AND' <conditions>
| <condition> 'OR' <conditions>
| []
<order_clause> ::= <data> ASC
| <data> DESCdelete
DELETE FROM users WHERE id = 1;
DELETE FROM users;
<statements> ::= <delete_data>
<delete_data> ::= <delete_all>
| <conditional_delete>
<delete_all> ::= 'DELETE' 'FROM' 文法整合
<statement> ::= <create_database>
| <create_table>
| <show_database>
| <use_database>
| <insert_data>
| <select_data>
| <delete_data>
<delete_data> ::= 'DELETE' 'FROM' 'IDENTIFIER'
<use_database> ::= 'USE' 'IDENTIFIER'
<show_database> ::= 'SHOW' 'DATABASES'
<create_database> ::= 'CREATE' 'DATABASE' 'IDENTIFIER'
<create_table> ::= 'CREATE' 'TABLE' 'IDENTIFIER' '(' <columns> ')'
<columns> ::= <column> <column_list>
| ',' <column> <column_list>
<column_list> ::= ',' <column> <column_list>
| ',' <column>
| ''
<column> ::= 'IDENTIFIER' <data_type> <constraints>
<data_type> ::= 'INT'
| 'VARCHAR' '(' NUMBER ')'
| 'DECIMAL' '(' NUMBER ',' NUMBER ')'
<constraints> ::= <constraint> <constraints>
| <constraint>
<constraint> ::= 'PRIMARY KEY'
| 'NOT NULL'
<insert_data> ::= 'INSERT' 'INTO' 'IDENTIFIER' '(' <data_columns> ')' <insert_clause>
<data_columns> ::= <data> ',' <data_columns>
| <data>
<insert_clause> ::= 'VALUES' <values_clause>
| 'SELECT' <select_data>
<values_clause> ::= '(' <datas> ')'
| '(' <datas> ')', <values_clause>
<datas> ::= <datas> ',' <data>
| <data>
<data> ::= 'IDENTIFIER'
| "'" 'IDENTIFIER' 'IDENTIFIER' "'"
| "'" 'IDENTIFIER' "'"
| 'NUMBER'
<select_data> ::= <select_all>
| <simple_select>
| <conditional_select>
| <ordered_select>
<select_all> ::= 'SELECT' '*' <from_clause>
<simple_select> ::= 'SELECT' <data_columns> <from_clause>
<conditional_select> ::= 'SELECT' <data_columns> <from_clause> <where_clause>
<ordered_select> ::= 'SELECT' <data_columns> <from_clause> <order_by_clause>
<from_clause> ::= 'FROM' <data>
<order_by_clause> ::= 'ORDER BY' <order_clause>
<order_clause> ::= <data> ASC
| <data> DESC
<delete_data> ::= <delete_all>
| <conditional_delete>graph G {
// Define node attributes
node [shape=box, style=filled, fontname="Helvetica", fontsize=12, fillcolor="#E0E0E0", color="#333333"];
// Statements
statements [label="<statements>"];
create_database [label="<create_database>"];
create_table [label="<create_table>"];
show_database [label="<show_database>"];
use_database [label="<use_database>"];
insert_data [label="<insert_data>"];
select_data [label="<select_data>"];
delete_data [label="<delete_data>"];
// rules
create_database_rule [label="CREATE DATABASE IDENTIFIER"];
use_database_rule [label="USE IDENTIFIER"];
show_database_rule [label="SHOW DATABASES"];
insert_data_rule [label="INSERT INTO IDENTIFIER ( <data_columns> ) <insert_clause>"];
insert_clause_rule1 [label="VALUES <values_clause>"];
insert_clause_rule2 [label="SELECT <select_data>"];
values_clause_rule1 [label="( <datas> )"];
values_clause_rule2 [label="( <datas> ), <values_clause>"];
data [label="<data>"];
data_clause [label="<datas> , <data>"];
data_rule1 [label="' IDENTIFIER IDENTIFIER '"];
data_rule2 [label="' IDENTIFIER '"];
data_rule3 [label="NUMBER"];
// Create table
create_table_rule [label="CREATE TABLE IDENTIFIER ( <columns> )"];
create_columns [label="<create_columns>"];
create_column [label="<create_column>"];
create_column_rule [label="'IDENTIFIER' <data_type> <constraints>"];
data_type [label="<data_type>"];
constraints [label="<constraints>"];
constraint [label="<constraint>"];
// Constraints options: PRIMARY KEY, NOT NULL
primary_key [label="PRIMARY KEY"];
not_null [label="NOT NULL"];
// Data type options: INT, VARCHAR, DECIMAL
int_type [label="INT"];
varchar_type [label="VARCHAR (NUMBER)"];
decimal_type [label="DECIMAL (NUMBER, NUMBER)"];
// Recursion connection, <create_columns> -- <create_column> -- <create_columns>
create_columns -- create_columns [label=",", color=red]; // Undirected recursion
create_columns -- create_column [color=red]; // Undirected
// Recursion connection, <constraints> -- <constraint> -- <constraints>
constraints -- constraints [color=red]; // Undirected recursion for constraints
constraints -- constraint [color=red]; // Undirected
// Connecting statements
statements -- create_database;
statements -- create_table;
statements -- show_database;
statements -- use_database;
statements -- insert_data;
statements -- select_data;
statements -- delete_data;
// Connecting create database rule
create_database -- create_database_rule;
// Connecting create table
create_table -- create_table_rule;
create_table_rule -- create_columns;
create_columns -- create_column;
create_column -- create_column_rule;
create_column_rule -- data_type;
create_column_rule -- constraints;
data_type -- int_type;
data_type -- varchar_type;
data_type -- decimal_type;
constraints -- constraint;
constraint -- primary_key;
constraint -- not_null;
// Connecting show database
show_database -- show_database_rule;
// Connecting use database
use_database -- use_database_rule;
// Connecting insert data
insert_data -- insert_data_rule;
insert_data_rule -- data_columns [label="<data_columns>", fontsize=10];
data_columns -- data;
data_columns -- data_columns [label=",", color=red];
data_columns -- data [color=red];
insert_data_rule -- insert_clause [label="<insert_clause>", fontsize=10];
insert_clause -- insert_clause_rule1;
insert_clause -- insert_clause_rule2;
insert_clause_rule1 -- values_clause_rule1;
insert_clause_rule1 -- values_clause_rule2 [label="<values_clause>", color=red];
values_clause_rule1 -- data;
values_clause_rule1 -- data_clause;
insert_clause_rule1 -- insert_clause_rule1 [label=",", color=red];
data -- data_rule1;
data -- data_rule2;
data -- data_rule3;
// Connecting select data
select_data -- select_data_rule;
select_data_rule -- select_all;
select_data_rule -- simple_select;
select_data_rule -- ordered_select;
select_data_rule -- from_clause;
select_data_rule -- order_by_clause;
// Connecting delete data
delete_data -- delete_data_rule;
delete_data_rule -- delete_all;
// Select All
select_all [label="SELECT * <from_clause>"];
simple_select [label="SELECT <data_columns> <from_clause>"];
ordered_select [label="SELECT <data_columns> <from_clause> <order_by_clause>"];
// From clause
from_clause [label="<from_clause>"];
order_by_clause [label="<order_by_clause>"];
// Order by clause
order_clause [label="<order_clause>"];
order_clause -- data;
order_clause -- "ASC";
order_clause -- "DESC";
// Delete data
delete_all [label="DELETE FROM"];
}SLY库-读后总结
SLY 的基本概念
SLY(SLY is a LALR(1) parser)是一个用于构建上下文无关文法解析器的 Python 库,基于 LALR(1) 算法。
- 上下文无关文法(CFG):
- SLY 使用上下文无关文法来定义语言的语法。上下文无关文法是由终结符、非终结符、产生式和起始符组成的。
- 解析器:
- SLY 是一个 LALR(1) 解析器,它能够处理 LALR(1) 文法,即左先行和向前查找的文法。LALR(1) 是一种广泛使用的解析器类型,常用于编译器的语法分析阶段。
- 词法分析器:
- SLY 也提供词法分析功能,能够将输入字符串分解为一系列记号(tokens),供解析器使用。
文档阅读记录1
token
定义
- 长标记要在短标记之前指出(在写正则表达式的部分,上面顺序无所谓)
重映射
- Token Remapping
文本字符
self.nesting_level -=1用这个维护更好both its
typeandvalueattributes are set to the character itself.class MyLexer(Lexer): literals = { '{', '}' } def __init__(self): self.nesting_level = 0 @_(r'\{') def lbrace(self, t): t.type = '{' # Set token type to the expected literal self.nesting_level += 1 return t @_(r'\}') def rbrace(t): t.type = '}' # Set token type to the expected literal self.nesting_level -=1 return t
ignore的使用
关于return返回
标题 : Adding Match Actions (RTFM)
关于调试的技巧
讲方法赋到令牌上
You can temporarily attach a method a token
文法解析
Sly 使用的 LALR(1) 解析算法是 自左向右扫描,向左归约(LR(1))的解析方法。具体来说,解析器会从输入串的左侧开始扫描(即自左向右),并尝试根据当前输入符号和栈顶的状态进行规约。这个过程是“向左归约”的意思,即它尝试使用文法的规则,将输入串归约为更高层次的符号。
LR分析:LR分析器的工作方式是从左到右扫描输入
LR(0):仅根据栈的内容做出决策,没有看未来的token。
LR(1):利用一个lookahead(前瞻)token来做决策。在你的例子中,实际上是LR(1)的情况,因为分析器在处理
term时,有一个lookahead,能看到*。- Sly使用内部机制来实现lookahead功能, 代码已经封装好了,所以写代码不需要考虑这个问题
关于返回的值赋给谁
- 赋给token :exp, 则def exp
在优先级声明中,标记按从最低到最高优先级的顺序排列。
- left: 左结合
precedence = ( ('left', PLUS, MINUS), ('left', TIMES, DIVIDE), )Parser Debugging
反思
- 对大二
- 编译原理课程的意义
- 对自己
- 没有gpt,一点一点摸索,有点像大一做网址的时候了
- 网上没有现成的
- 做有复杂的项目之前一定要通读 RTFM
- GPT带来的影响,AI 回答不对,都不知道怎么改bug了
- 学会正确提问很重要,这样才会得到正确的回答
- prompt工程
- 感受理论和实践相结合
- 课程学的太理论学完不知道怎么用
- 标准化测试
- 懂得做减法
- kiss原则
- 最后还是操控csv来实现储存,这样和文件管理不一样不大有差
- 数据抽象层
- 安全——sql注入问题
- 插入——选择——性能对比——慢——试着优化——还是慢——为什么——rust安全性能好,比python更适合做尝试?更有意义?
参考资料
- Python Lex Yacc手册_python yacc-CSDN博客
- [weekly/编译原理/65.精读《手写 SQL 编译器 - 文法介绍》.md at master · ascoders/weekly](https://github.com/ascoders/weekly/blob/master/编译原理/65.精读《手写 SQL 编译器 - 文法介绍》.md)
- Graphviz - 开发工具 - 程序员的自我修养
- 数据库前世今生- 维基百科