DataWhale AI 春训营
6 min
DataWhale AI 春训营
第三届世界科学智能大赛新能源赛道:新能源发电功率预测
大赛背景
为推动科学智能领域创新发展,在上海市政府的指导下,上海科学智能研究院携手复旦大学在上智院平台发布“第三届世界科学智能大赛”。大赛设置航空安全、材料设计、合成生物、创新药、新能源五大赛道,配有高额奖金池,面向全球人才开放,旨在推进科学智能技术创新,挖掘顶尖创新团队,构建科学智能生态,激发科学智能发展新动能。
过程记录
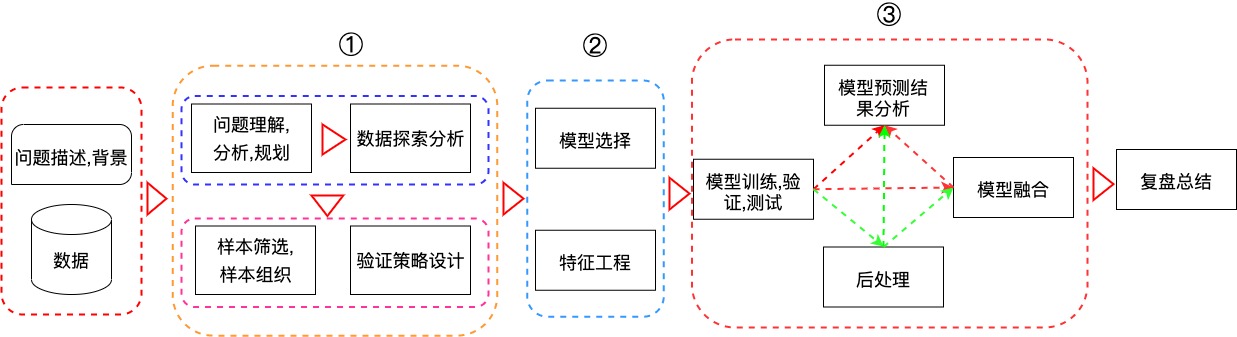
整体流程
环境与库说明
主要依赖库
from netCDF4 import Dataset # 处理NetCDF格式气象数据
import numpy as np # 数值计算
import pandas as pd # 数据框操作
import matplotlib.pyplot as plt # 可视化
from sklearn.model_selection import KFold # 交叉验证
from sklearn.metrics import mean_squared_error # 评估指标
import lightgbm as lgb # 梯度提升框架
from tqdm import tqdm # 进度条显示核心库功能解析
- netCDF4
- 处理气象领域标准的NetCDF格式
Dataset对象用于读取.nc文件variables属性获取数据维度信息- 支持切片操作获取多维数组数据
- Pandas
- 时间序列处理:
date_range生成日期序列 - DataFrame操作:
concat合并数据,reset_index重置索引 - 数据清洗:
dropna处理缺失值
- 时间序列处理:
- LightGBM
- 高效的梯度提升决策树实现
- 支持GPU加速和并行学习
- 内置交叉验证和早停机制
- Sklearn
- KFold实现数据分折
- RMSE作为模型评估指标
数据预处理流程
数据加载与解析
def get_data(path_template, date):
dataset = Dataset(path_template.format(date), mode='r')
channel = dataset.variables["channel"][:]
data = dataset.variables["data"][:]
mean_values = np.array([np.mean(data[:, :, i, :, :][0], axis=(1, 2)) for i in range(8)]).T
return pd.DataFrame(mean_values, columns=channel)- 特征维度说明:24小时×8通道×11×11网格
- 空间维度聚合:对11×11网格取均值
- 时间维度保留:保持24小时时间序列
特征工程
def feature_combine(df):
df_copy = df.copy()
df_copy["wind_speed"] = np.sqrt(df['u100']**2 + df['v100']**2)
df_copy["h"] = df_copy.index % 24
return df_copy- 合成特征:利用向量合成计算风速
- 时间特征:添加小时周期特征
- 特征维度扩展:从8维扩展到10维
数据可视化
plt.figure(figsize=(20,10))
for i in range(9):
plt.subplot(3, 3, i+1)
plt.plot(hours, train.iloc[:24, i])
plt.title(train.columns.tolist()[i])- 可视化目的:检查数据分布和周期性
- 关键观察点:
- 温度、湿度等参数的日变化规律
- 风速特征的波动特性
- 功率输出的时间相关性
模型构建与训练
交叉验证策略
kf = KFold(n_splits=5, shuffle=True, random_state=seed)- 5折交叉验证:平衡计算成本和验证可靠性
- 数据划分策略:时间序列保持连续性的随机划分
- OOF预测:out-of-fold预测用于模型评估
3.2 LightGBM参数解析
params = {
'boosting_type': 'gbdt', # 传统GBDT算法
'objective': 'regression', # 回归任务
'metric': 'rmse', # 评估指标
'num_leaves': 2**8, # 控制模型复杂度
'learning_rate': 0.1, # 学习步长
'feature_fraction': 0.8, # 特征采样率
'bagging_fraction': 0.8, # 数据采样率
'lambda_l2': 10, # L2正则化
}- 调参要点:
- 学习率与迭代次数的平衡
- 正则化项防止过拟合
- 采样策略提升泛化能力
3.3 训练过程监控
model = lgb.train(params, train_matrix, 3000,
valid_sets=[train_matrix, valid_matrix],
early_stopping_rounds=200)- 早停机制:防止过拟合
- 双验证集监控:同时观察训练集和验证集表现
- 最佳迭代选择:自动保存最优模型
结果后处理
预测值处理
lgb_test = [item for item in lgb_test for _ in range(4)]- 数据对齐:将每小时预测扩展到15分钟间隔
- 业务适配:满足电力系统调度需求
- 时序保持:维持时间序列的连续性
结果保存
output = pd.read_csv("./output/output1.csv")
output["power"] = lgb_test
output.to_csv('output/output1.csv')- 格式要求:符合提交规范的时间-功率格式
- 索引处理:保持时间戳的正确对应
- 数据验证:检查预测值范围合理性
优化方向建议(AI tutor)
特征工程扩展
- 时间特征:添加周周期、节假日标志
- 气象衍生:计算温湿指数、风寒指数
- 滞后特征:加入历史时刻特征
模型优化
- 超参数搜索:使用Optuna进行贝叶斯优化
- 模型融合:结合XGBoost和神经网络
- 时序特性:引入LSTM等序列模型
数据层面优化
- 空间特征:保留区域分布信息
- 多尺度数据:融合卫星观测数据
- 异常值处理:使用3σ原则清洗数据
核心知识点总结
| 模块 | 关键技术点 | 实现方法 | 优化方向 |
|---|---|---|---|
| 数据读取 | NetCDF解析 | 维度切片+均值聚合 | 保留空间分布特征 |
| 特征工程 | 向量合成 | 风速合成公式 | 添加大气稳定度指标 |
| 模型训练 | LightGBM调参 | 交叉验证+早停机制 | 自动化超参数搜索 |
| 结果输出 | 时序对齐 | 预测值重复插值 | 考虑时间衰减因子 |